一、背景:算力网络的分层需求
随着大规模AI训练集群和推理集群的部署,算力互联网络正在形成明显的分层架构:
Scale Across网络(中短距):机架间、机柜间、机房内的算力节点互联,距离通常在数百米至数公里以内,延迟敏感,对成本极度敏感,是今天GPU/NPU集群组网的核心。
算力骨干网(长距):跨数据中心、跨城市的算力调度,传输距离数十至数千公里,需要频谱效率与线路放大,相干通信是不可替代的技术路线。
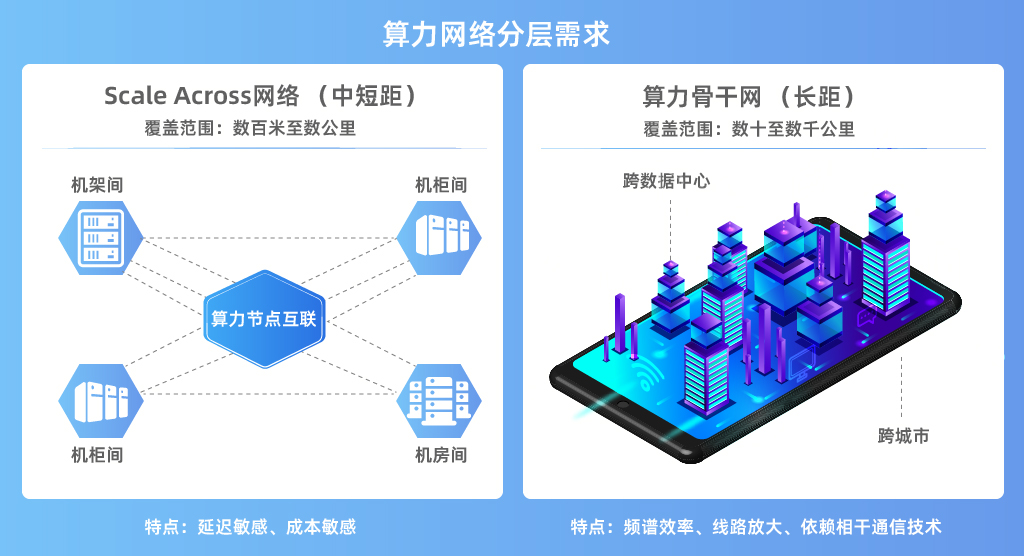
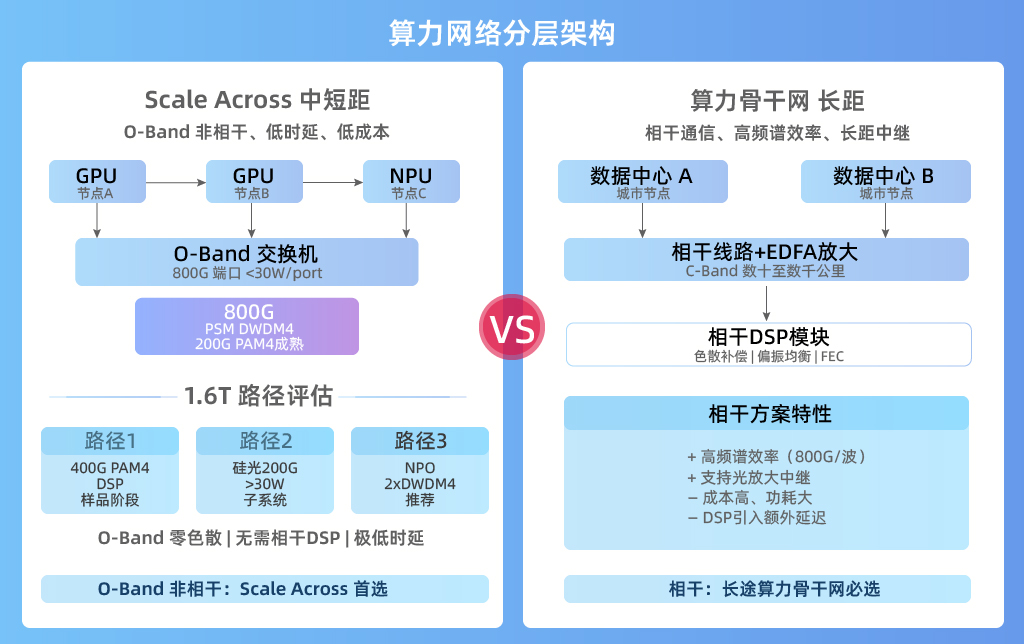
这两类网络对光模块的需求截然不同。长距算力网必须采用相干通信,而Scale Across中短距算力网则完全没有必要使用相干方案——相干系统引入的额外成本、功耗与延迟,在此场景下都是纯粹的负担。
二、为什么Scale Across选择O-Band非相干方案?
O-Band(1260–1360 nm)在中短距传输中具备三个关键优势:
- 零色散窗口:O-Band工作于光纤色散零点附近,无需色散补偿,信号完整性好,适配PAM4等高阶调制格式,且无需DSP色散均衡开销。
- 低时延:非相干架构去除了相干DSP的处理延迟,端到端时延极低,这对AI训练中All-Reduce等集合通信操作至关重要。
- 最经济的系统成本:无需本振激光器、90°光混频器和复杂DSP,硅光方案即可实现,BOM成本大幅低于相干方案。
在Scale Across场景下,O-Band非相干方案提供了最优的成本-延迟-功耗三角平衡。
三、当前产品覆盖能力:至800G无障碍
目前基于单波100G O-Band的非相干方案,可以完整覆盖到800G速率。
未来, 800G方案可基于成熟的单通道200G PAM4实现,技术风险低,系统完整度高。
| 速率 | 技术方案 | 状态 |
|---|---|---|
| 100G | QSFP28,O-Band DWDM1,单波100G PAM4硅光 | 量产成熟 |
| 400G | QSFP-DD,O-Band PSM4,DWDM4,单波100G PAM4硅光 | 样品 |
| 800G | OSFP,O-Band PSM,DWDM4,单波200G PAM4硅光 | 研发中 |

四、1.6T Scale Across:三条技术路径的评估
向1.6T演进时,存在三条可行路径,技术成熟度与工程约束各异:
路径一:1.6T PSM DWDM4(单波400G PAM4, 硅光调制)
这是最激进的单模组方案。单波400G PAM4的DSP目前尚未大规模量产,但业内已出现1.6T DR4样品,意味着400G PAM4 DSP的芯片样品已经存在。从样品到量产还需时间,预计是中期可期的方向。
路径二:1.6T 2×PSM DWDM4(单波200G PAM4,硅光调制)
基于成熟的200G PAM4硅光调制器,通过两个800G子模块堆叠实现1.6T。技术上可以实现,但功耗问题是核心瓶颈:
若整体功耗超过30W,交换机端口无法直接为模块供电,需要额外供电设计,破坏了可插拔模块的即插即用性。该方案在功耗限制下仅适合特定子系统部署,难以成为主流Scale Across方案。
路径三:1.6T NPO(Near Package Optics)2× (PSM DWDM4) (单波200G PAM4,硅光调制)✓ 推荐方案
NPO架构将光引擎靠近或集成到交换芯片封装附近,从根本上解决了功耗和信号完整性的双重矛盾:
- 电信号走线极短,SerDes功耗大幅降低
- 不再受限于标准可插拔模块的功耗预算
- 基于成熟的2×PSM DWDM4架构,技术路径清晰
- 可以完整实现1.6T O-Band非相干Scale Across
这是当前阶段实现1.6T Scale Across最可行的工程化路径。

五、技术路径对比总结
| 方案 | PAM4调制 | 速率 | DSP成熟度 | 功耗 | 交换机直接支持 | 推荐场景 |
|---|---|---|---|---|---|---|
| 800G OSFP PSM DWDM4 | 单波200G | 800G | 成熟 | ≤18W | ✓ | 主流Scale Across |
| 1.6T PSM DWDM4(400G PAM4) | 单波400G | 1.6T | 样品阶段 | 待定 | 待验证 | 中期演进方向 |
| 1.6T 2×PSM DWDM4 | 单波200G | 1.6T | 成熟 | >30W | ✗ | 子系统特定部署 |
| 1.6T NPO 2×PSM DWDM4 | 单波200G | 1.6T | 成熟 | 可控 | ✓(NPO架构) | 推荐主路线 |
六、结论
ScaleAcross算力网络的本质诉求是:低延迟、低成本、高密度、易运维。在中短距算力互连场景,相干通信引入的系统复杂度在此场景完全没有必要,O-Band非相干方案天然契合这一诉求。
1. O-Band非相干400G、800G PSM DWDM4方案技术成熟,已经可规模部署。
2. O-Band非相干1.6T DWDM通过设计创新均可以实现。